

直接逆強化学習を用いたロボット制御(No. 0061, 0097)
|
|
<< 技術一覧に戻る |

概要
密度比推定による直接逆強化学習を用いたロボット制御アルゴリズム。
人工知能の世界市場規模は、年平均35%で成長し2026年までに2,990億米ドルに達すると予測されています。人工知能とは、学習によって人間と同じような問題解決能力をコンピュータシステムに持たせることをいいます。人間の知能は、現在の意識と感情の組み合わせで機能しますが、AIは複雑な数学的手法を用いて後者を模倣することを目的としています。人間とインターラクションできる人工システムを開発するためには、人間の行動を観察して理解することが非常に重要です。人間の意思決定プロセスは、選択された行動に対する報酬/コストに影響されるため、観察された行動から報酬/コストを推定することで課題を定式化することができます。しかし、適切な報酬/コスト関数をどのように設計し、準備するかということが非常に重要となります。既知のアルゴリズムは、環境のモデルが利用可能な場合でも、非常に時間がかかるものでした。銅谷賢治教授を中心とした研究グループは、上記の問題点を克服し、より信頼性が高く迅速な制御スキームを提供する優れたロボット制御アルゴリズムを開発しました。

応用
- ロボット制御
- ウェブ体験の分析 - 予測
- 模倣学習
利点
- モデルフリーの手法 - 環境のダイナミクスを知る必要がない
- データ効率 - データ収集が容易
- 計算効率が高い - 速い
画像クリックで拡大
技術のポイント
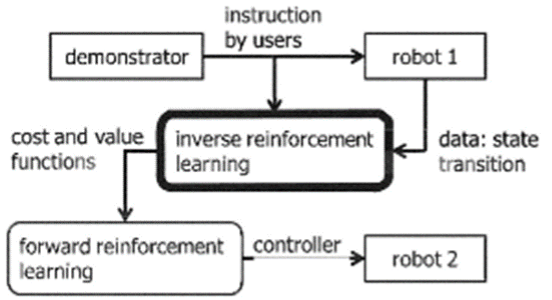
この新しいアルゴリズムには2つの要素があります。(1)密度比推定による制御有無の状態遷移確率比の学習、(2)正則化最小二乗法による遷移確率比に適合したコストと価値関数の推定。各ステップに効率的なアルゴリズムを用いることで、他の逆強化学習法と比較してデータや計算量の効率化が図られています。ロボットへの実装では,デモ担当者がロボットを制御してタスクを達成し、そのときの状態と行動のシーケンスが記録されます。そうして逆強化学習アルゴリズムがコストと価値関数を推定し、それが異なるロボットの順強化学習コントローラに与えられます。
メディア掲載・プレゼンテーション
問い合わせ先
![]()
OIST Innovation 技術移転セクション
![]() tls@oist.jp
tls@oist.jp
![]() +81(0)98-966-8937
+81(0)98-966-8937