

Research Storage
This site is discontinued.
Please go to SCDA-guide.oist.jp
Access the storage
The storage systems at OIST are available for all OIST researchers. You don't need an account on the cluster, and you don't need to apply for access. You can mount the storage systems remotely on your desktop. You can also access them directly through SSH and through rsync. Please see our section on moving data for details.
Each unit has their own folders on the system, and you normally have access only to the storage folders for your unit. If you are a student you may need to ask your unit leader to add you to the unit member list before you can access the unit storage.
Storage Systems
We have three types of storage systems at OIST. They mostly differ by the time frame they store data.
|
|
Long Term storageSecure storage and long-term archiving of research data. Bucket is a high-capacity, expandable online storage system meant for long-term storage. It is regularly backed up off-site to Naruto, the tape system in Nago city. Use this for any data you wish to save for the future. Comspace is a self-managed storage system where units and sections can create filesystems and manage user access by themselves.
|
||||||||||||||||
|
|
Compute StorageQuickly read and write data during computations. Deigo Flash and Saion Work are fast, in-cluster storage systems that prioritize speed over capacity. They are not backed up and not expandable. Scratch is node-local storage that is very fast, but is low capacity and not accessible outside each node. Use the compute storage for temporary files during computation, then copy any results you want to keep to Bucket for long-term storage. Finally, clean up these systems at the end of your job.
|
||||||||||||||||
|
|
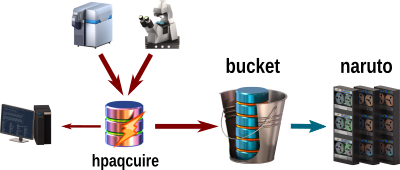
Transient storage and transferVery short-term storage used to transfer data from one place to another. Some instruments generate large amounts of data. Use Hpaqcuire to quickly transfer the data to Bucket for long-term storage; or to your own local workstation. Datacp is a specialized partition with very fast access to all storage at OIST. Use it when you need to transfer large (TB+) data sets from outside or between other storage systems. Datashare lets you quickly share public data between users on Deigo.
|
||||||||||||||||
|
|
Personal DataIn your home directory, you can store your own configuration files, source code, and documents.
|






Other systems
In addition, we have a few systems that aren't used for storing research data but are useful in other ways. Most of these are managed by the IT section.

Software
Organize your personal and unit-specific software.
/apps
Github
Organisation
This is the overall organisation of the compute storage systems:
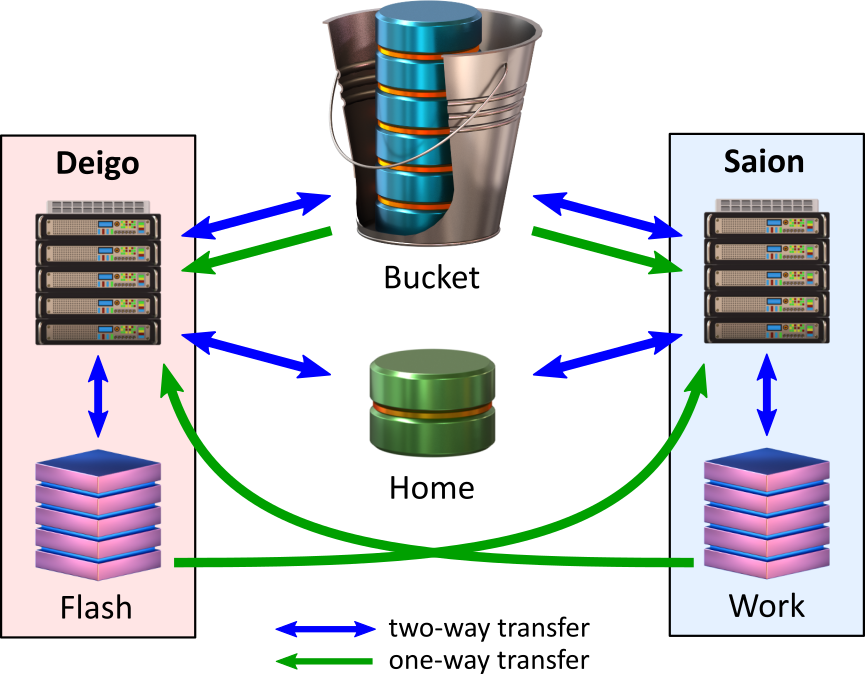
Each cluster has read and writable fast local storage ("Flash" for Deigo and "Work" for Saion).
Bucket is read and writable on the login nodes and through "datacp", and read-only on the compute nodes. Your home directory is read and writable from anywhere.
In addition, the local storage of each cluster is available read-only from the other cluster. You can do the CPU-bound steps of a computation on Deigo, then GPU-based computation on Saion without having to manually copy data between them.
Workflow
It is helpful to see a practical example of how to use these systems. Here is the typical workflow for your data:
- Use transient storage such as HPacquire to move data from instruments to the OIST storage systems or your own workstation. You will usually move it to long-term storage (Bucket) for safekeeping. You can copy any local data on your workstation directly to Bucket using scp or by mounting Bucket as a remote directory. The data stored on Bucket is periodically backed up off-site to the Naruto tape system.
- For running jobs on your data, keep your data on Bucket. Read it directly from Bucket on the compute nodes. Use the local cluster storage (Flash for Deigo, Work for Saion) for reading and writing data as you work. At the end, copy the results back to Bucket, using "scp". Then clean up the local storage.
You can also read data from the local storage of the other cluster. You can split up your computation into separate jobs, with one part running on Deigo, another on Saion, and read the output directly from the previous job. We have more detail and examples on our Deigo page.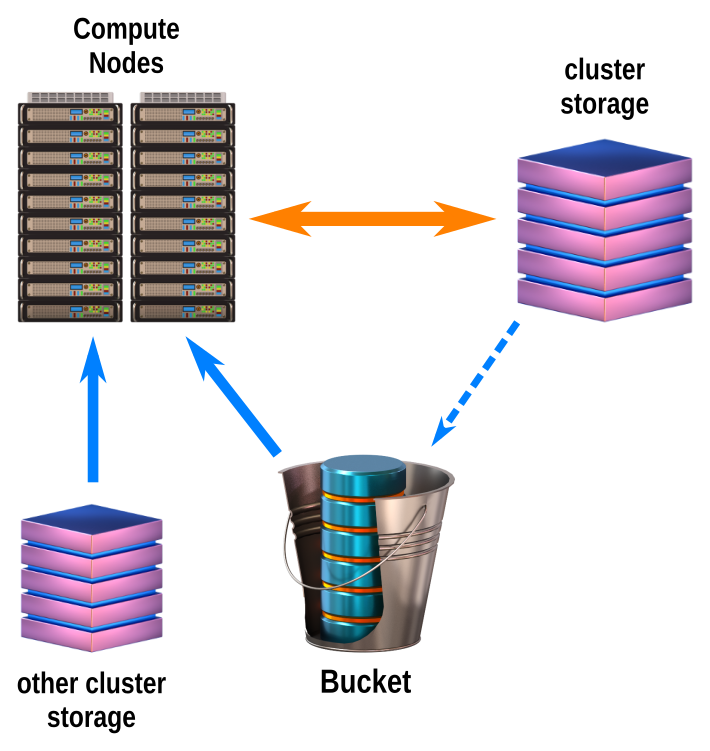
- If you want to use your own software, install it in /apps/unit/ (or perhaps in your Home) then use it for your analysis and data-processing. You can use the OIST Github account to safely keep your source code if you are developing your own applications.
- When you need to share data with specific members of your unit or with other OIST members, you can use Comspace. It lets you create a remote share for, say, a specific project and manage fine-grained access rights for individual users. It is mostly meant for access as a remote folder.