

強化学習アルゴリズムに基づく環境制御 (No. 0123, 0124)
|
|
<< 技術一覧に戻る |

概要
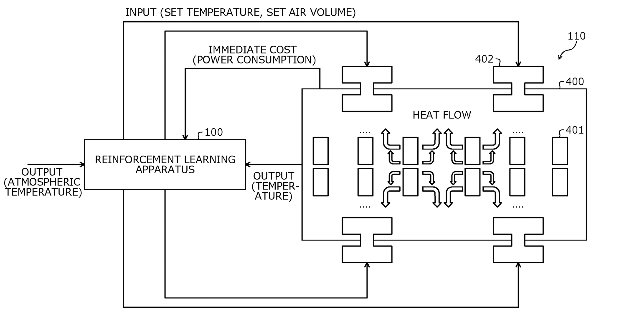
機械学習を用いたソリューションは、顧客体験の向上やビジネスにおける競争力の強化のために、世界中で採用されつつあります。従来の強化学習技術では、制御対象(温度制御など)に対する入力に応じた制御対象の即時コストや即時報酬に基づき、累積コストや累積報酬を表す価値関数を最小化または最大化する制御則を学習し、制御対象への入力値を決定します。しかし、制御対象の状態や、制御対象への入力に対応する即時コストや即時報酬が不明である場合があります。この場合、従来の技術では制御対象に対する望ましい入力値を精度よく決定するのは難しく、さらにフィードバック係数行列を効率よく更新することが困難な場合がありました。銅谷賢治教授を中心とする研究グループが開発したアルゴリズムでは、上記の問題点を解決し、より信頼性の高い制御が可能となりました。

応用
- 部分観測制御
- 線形二次制御(LQR)
- サーバールームの温度制御
- 発電機制御
利点
- 制御対象の状態の観測が不要
- 制御対象への入力に対する即時コストや報酬の情報が不要
画像クリックで拡大
技術のポイント
本技術は、部分観測環境において制御ポリシーを学習する新しい強化学習アルゴリズムに基づくものです。学習された制御ポリシーを用いることで、環境条件などを効率的に管理することができます。具体的には、過去と現在の入力(例:設定温度)と出力(例:温度センサー)から価値関数(例:消費電力モデル)の係数を決定し、これに基づいて制御ポリシーを作成します。さらに、フィードバック係数を適時に更新する方法も提供されるので、総コスト(例:累積消費電力)を効率的に最小化することが可能となります。
メディア掲載・プレゼンテーション
問い合わせ先
![]()
OIST Innovation 技術移転セクション
![]() tls@oist.jp
tls@oist.jp
![]() +81(0)98-966-8937
+81(0)98-966-8937