

システム生物学グループ
研究の目的
人間や動物は、報酬をより多く得られるように学習し意思決定をすることができます。システム生物学グループの研究目的は、報酬をもととした学習や意思決定の神経メカニズムを解明することです。強化学習などの計算理論的な立場から動物の行動や脳活動を説明することを目標とし、以下の二つの作業仮説を神経生理実験によって検証しています。
作業仮説
神経修飾物質は報酬にもとづいた学習のパラメータを調節している
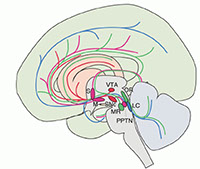 強化学習理論は報酬最大化に基づいた学習方法を提供しますが、 ここで提案される学習アルゴリズムは、設計者が注意深くパラメータ を設定しないとうまく動作しません。しかしながら人間や動物は 変動する環境においてもうまく新しい行動を学習することが できます。脳はパラメータの調節も自分自身で行えるメカニズムが あるのでしょう。私たちは、「これらのパラメータは脳内修飾物質 によって調節されている」という仮説を提案し (Doya 2002)、 以下のように考えています。
強化学習理論は報酬最大化に基づいた学習方法を提供しますが、 ここで提案される学習アルゴリズムは、設計者が注意深くパラメータ を設定しないとうまく動作しません。しかしながら人間や動物は 変動する環境においてもうまく新しい行動を学習することが できます。脳はパラメータの調節も自分自身で行えるメカニズムが あるのでしょう。私たちは、「これらのパラメータは脳内修飾物質 によって調節されている」という仮説を提案し (Doya 2002)、 以下のように考えています。
- ドーパミンは報酬の予測誤差をコードしている。
- セロトニンは未来で得られる報酬の時定数を調節している。
- ノルアドレナリンは探索の広さを調節している。
- アセチルコリンは学習速度を調節している。
大脳基底核-新皮質における強化学習モデルの実装
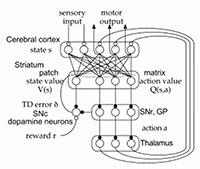 中脳のドーパミンニューロンは、動物が期待していた報酬よりも 実際に得た報酬の方が多いときに強く反応します。このドーパミン ニューロンの振る舞いは、強化学習アルゴリズムで用いられる 報酬予測誤差信号と非常に似ているものです。ドーパミンニューロン は大脳基底核の入力部に相当する線条体にその情報を送っています。 私たちは大脳基底核やそこへ入力信号を送る新皮質で、強化学習 アルゴリズムが実装されている可能性を提案し(Doya, 2000, 2002) 検証しています。
中脳のドーパミンニューロンは、動物が期待していた報酬よりも 実際に得た報酬の方が多いときに強く反応します。このドーパミン ニューロンの振る舞いは、強化学習アルゴリズムで用いられる 報酬予測誤差信号と非常に似ているものです。ドーパミンニューロン は大脳基底核の入力部に相当する線条体にその情報を送っています。 私たちは大脳基底核やそこへ入力信号を送る新皮質で、強化学習 アルゴリズムが実装されている可能性を提案し(Doya, 2000, 2002) 検証しています。
参考文献
- Doya K., (2000),
Complementary roles of basal ganglia and cerebellum in learning and motor control.
Current Opinion in Neurobiology, 10(6), 732-739. - Doya K., (2002),
Metalearning and neuromodulation.
Neural Networks, 15, 495-506
実験テーマ
現在我々は上記の仮説を検証するために以下の実験を行っています。
- 目的志向型の行動中におけるセロトニンニューロンの神経活動記録 とセロトニン濃度測定
- ラットの二択課題における大脳基底核の神経活動記録
- 人の意思決定における機能的磁気共鳴映像法(fMRI)測定
- 連続行動の学習メカニズム